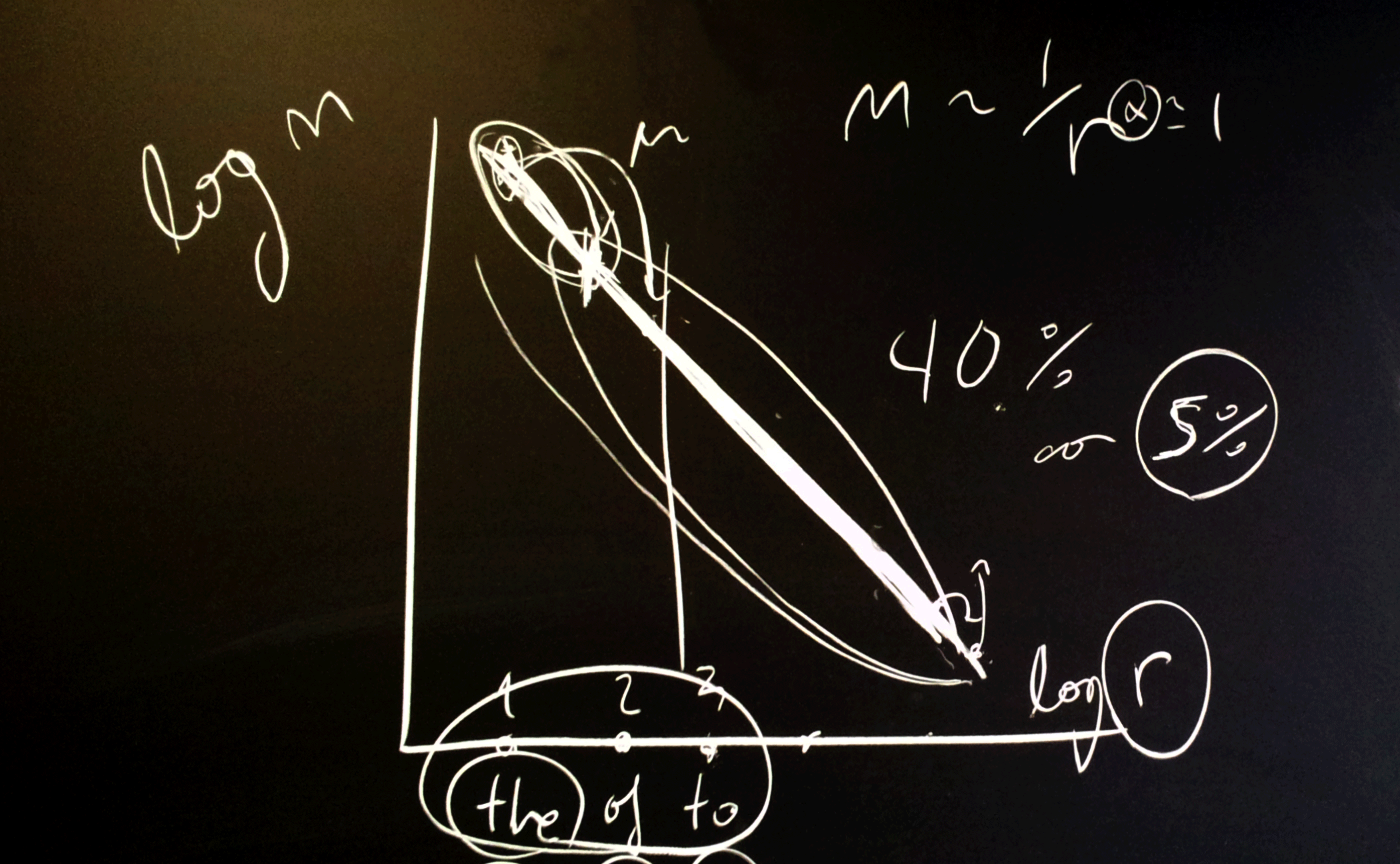Hace 80 años el lingüista estadounidense George Kingsley Zipf planteó una relación matemática que determina la frecuencia de las palabras en los textos, y que se suele cumplir cuando se excluyen los términos más raros. Ahora investigadores del Centre de Recerca Matemàtica, adscritos a la Universidad Autónoma de Barcelona, han analizado por primera vez la validez de esta ley con la enorme biblioteca electrónica del proyecto Gutenberg.
La ley de Zipf en su versión más sencilla, formulada en los años 30 por el lingüista estadounidense George Kingsley Zipf, determina que, de manera sorprendente, la palabra más frecuente de un texto aparece el doble de veces que la siguiente más frecuente, tres veces más que la tercera más frecuente, cuatro veces más que la cuarta más frecuente, y así sucesivamente.
La ley se puede aplicar en muchos otros campos, no sólo en la literatura, y se ha comprobado con más o menos rigor en grandes cantidades de datos, pero hasta ahora ha carecido de una comprobación con todo el rigor matemático y en una base de datos suficientemente grande como para dar validez estadística.
Investigadores del Centre de Recerca Matemàtica (CRM) –centro de la red CERCA de la Generalitat de Catalunya– adscritos al Departamento de Matemáticas de la Universidad Autónoma de Barcelona, han analizado por primera vez, con todo el rigor matemático y estadístico necesario, la validez de la ley de Zipf. Este estudio se enmarca dentro del proyecto Investigación en Matemática Colaborativa, impulsado por la Obra Social "la Caixa".
Para ello, han analizado toda la colección de textos en lengua inglesa del proyecto Gutenberg, una base de datos pública y gratuita con más de 30.000 obras en esta lengua. Se trata de una tarea sin precedentes: en el ámbito de la lingüística la ley nunca había sido comprobada en conjuntos de más de una docena de textos.
Según el análisis, si se ignoran las palabras más raras, aquellas que solo salen una o dos veces en todo un libro, el 55% de los textos se ajustan perfectamente a la ley de Zipf (en su formulación más general). Si se tienen en cuenta todas las palabras, también las más raras, este porcentaje es del 40%.
"Es muy sorprendente que la frecuencia de aparición de las palabras esté determinada por una fórmula con un solo parámetro libre. La famosa campana de Gauss, por ejemplo, ya necesita dos, posición y anchura, para ajustarse a los datos reales" explica Álvaro Corral, investigador del CRM adscrito al Departamento de Matemáticas de la UAB y coordinador de la investigación. "Si descartásemos palabras que aparecen 3, 4 o 5 veces en toda una obra, la proporción de libros que siguen la ley de Zipf podría llegar a porcentajes aún más altos".
En términos matemáticos, la ley afirma que si se ordenan todas las palabras por frecuencia de uso, la segunda más frecuente aparece ½ veces el número de veces que aparece la más frecuente; la tercera, 1/3 veces y, en general, la que ocupa la posición n aparece 1/n veces la más frecuente.
En realidad, la formulación más general de la ley incluye un exponente “a”, de modo que la relación es 1/na. Aunque complica un poco la fórmula, la frecuencia se ajusta muchísimo para valores de "a" muy cercanos a 1 (es decir, como si no se hubiera añadido ningún exponente). Y todavía hay otras formulaciones matemáticamente más complejas de la ley, pero todas con un solo parámetro libre.
Validar las tres formulaciones más usadas de la ley de Zipf
Los investigadores han estudiado la validez de las tres formulaciones más utilizadas de la ley de Zipf en todos los textos en lengua inglesa (31.075 libros) de la base de datos del proyecto Gutenberg, y han observado que una de estas formulaciones ajusta, con resultados estadísticamente significativos (p>0,05), la frecuencia de aparición de todas las palabras de más del 40% de los libros de la colección, unos textos que contienen entre 100 y más de un millón de palabras.
"La ley de Zipf ha generado mucho debate, pero siempre basándose en su validez en algunos ejemplos particulares" afirma Álvaro Corral. "Parece evidente que, en la actual era del Big Data y de las computadoras de altas prestaciones, se deberá enfocar los esfuerzos en el análisis de la ley a gran escala, y estos resultados son un primer paso en esta dirección".
"Aunque la literatura se considera una de las expresiones por antonomasia de la libertad creadora, ni los más grandes autores como Shakespeare o Dickens escapan a la tiranía de la ley de Zipf", concluye Corral.
La investigación, publicada recientemente en PLOS ONE, ha sido realizada por los investigadores Isabel Moreno Sánchez y Francisco Font-Clos bajo la dirección de Álvaro Corral. El CRM es un consorcio entre la Generalitat de Catalunya, el Institut d’Estudis Catalans (IEC) y la UAB.

La Academia Noruega de Ciencias ha reconocido al matemático alemán por avances fundamentales en el estudio de las ecuaciones diofánticas, un área clave de la teoría de números. El galardón, considerado el ‘Nobel de las matemáticas’, distingue contribuciones extraordinarias a lo largo de toda una carrera

Con motivo del Día Internacional de las Matemáticas, hablamos de esta disciplina que a menudo se percibe como abstracta o distante, pero que para quienes la estudian resulta profundamente fascinante. A través de la mirada de una estudiante universitaria de primer curso, nos acercamos a una de esas ideas matemáticas que conquistan por su sencillez aparente y la riqueza de los problemas que encierra.